
COVID-19 is the major issue worldwide and according to the recordings more than a million people died of this disease. Lets have a closer look at the conceptional linkage between the Artificial Intelligence, CONG and COVID-19
Your voice
Most of the time we use our voice to convey our wants, needs and problems to others. CONG regards the voice as an indicator of the state of certain areas of the body. THINK ABOUT IT 😱!!! The key lies in the generation of the voice and, most importantly, in the generation of the pitch. If you want to get more scientific facts about the 👉click here. …Back to the voice…The voice reflects the individual characteristics of the vocal source and the anatomy of the vocal tract. Basically CONG is able to detect any abnormalities during acoustic analysis. The parameters obtained by the acoustic analysis have the advantage of describing the voice objectively. With the existence of normative databases characterizing voice quality or using intelligent tools combining the various parameters, it is possible to distinguish between normal and pathological voice or even identify or suggest the pathology.
Artificial Intelligence
CONG analyses your voice and creates an image of it. This image is called spectrogram.
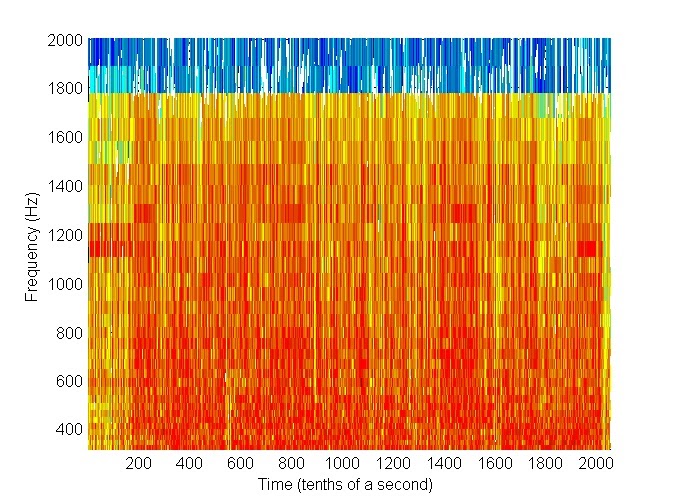
Now it is all about the artificial intelligence. This image reflects the features of your voice and basically the unique characteristics of your vocal source and the unique anatomy of the vocal tract. So by means of artificial intelligence those features are extracted out of the spectogram. To be precise the 👉MFCC👈 are applied to compute the features.
COVID-19 detection
Machine Learning is a sub-area os Artificial Intelligence. The first step is to build the decision rules for the machine learning. Those rules are formed by the referring data base, where the already extracted features are already assigned to related groups, e.g. COVID-19 positive and COVID-19 negative tested persons. Check here for 👉 more interesting Machine Learning content. Since COVID-19 is a respiratory disease that also affects you in your lungs, precisely the organs that are responsible for producing the sounds during speech, it is possible to define rules for such groups. In the next step extracted features will be applied to the existing data base, in order to compare the current takings with the existing ones. So basically the model is comparing the patterns and searching for match between them.
