

Before an introduction to Machine Learning and its algorithms a definition of the Machine Learning seems to be appropriate. Machine learning (ML) is the study of computer algorithms that improve automatically through experience. It is a subset of AI. ML algorithms are built as mathematical models. Such models use data, training data, in order to derive and make predictions. Machine learning is closely related to computational statistics, which focuses on making predictions using computers.
Machine Learning categories
Basically we can differentiate between two ML-categories. „Supervised“ and „unsupervised“. Supervised Maschine Learning algorithms need an example to recognize or detect a match. Only unsupervised Maschine Learning algorithms do not need any example and are based on self-learning procedures. They are using patterns for recognition and detection.
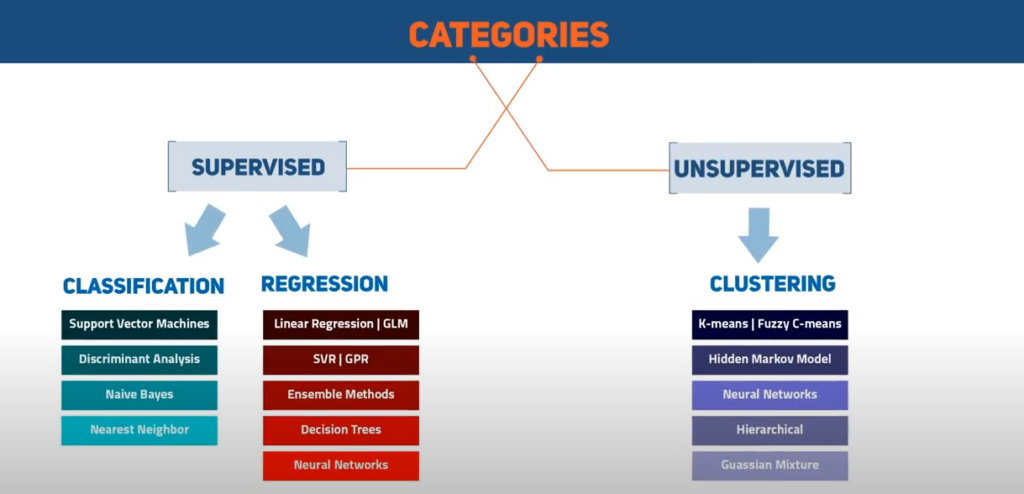
Below a couple of Machine Learning algorithms will be introduced, which are used in the areas of ML.
Machien Learning algorithms
Support Vektor Machine (SVM)
In machine learning, support vector machines (SVMs) are supervised learning models with associated learning algorithms that analyze data used for classification and regression analysis. The Support Vector Machine (SVM) algorithm is a popular machine learning tool that offers solutions for both classification and regression problems. Basically such algorithms can be used to map a specific result/feature to predefined group or cluster. It helps to assign the data to already known class or establish a valid relationship between independent variables.
K-Means
K-Means is a cluster method. K-means clustering is a method of vector quantization. This method is originally from signal processing. It aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest
mean, serving as a prototype of the cluster. This alagorithm is the most used one for grouping of results, because the centers of clusters are found pretty fast. The issues might be that this alagorith does not have to take the best solution. The decission is pending on the starting point. The algorithm has a loose relationship with the k-nearest neighbor classifier, a popular machine learning technique for classification that is often confused with k-means due to the name.
Naive Bayes
In statistics, Naïve Bayes classifiers are a family of simple “probabilistic classifiers”. It is based on applying Bayes’ theorem with strong (naïve) independence assumptions between the features. They are among the simplest Bayesian network models. But they could be coupled with Kernel density estimation and achieve higher accuracy levels. Basically this algorithm assignes each object to a class, to which it most probably belongs. So it is working based on the probability of the assignement result. The assignement is not only depending on the probability, but also on the costs of such an assignement. So the correctness of results is highly pending on the on the minimum-risks criteria.
Decision Tree
A decision tree is a decision support tool that uses a tree-like model of decisions and their possible consequences, including chance event outcomes, resource costs, and utility. It is one way to display an algorithm that only contains conditional control statements. it is very simple to apply algorithm and thus considered as a support tool. Decision trees are commonly used in operations research, specifically in decision analysis, to help identify a strategy most likely to reach a goal.
K-nearest neighbors (KNN)
In pattern recognition, the k-nearest neighbor algorithm (k-NN) is a non-parametric method proposed by Thomas Cover used for classification and regression. In both cases, the input consists of the k closest training examples in the feature space. The output depends on whether k-NN is used for classification or regression: In k-NN classification, the output is a class membership. An object is classified by a plurality vote of its neighbors, with the object being assigned to the class most common among its k nearest neighbors (k is a positive integer, typically small). If k = 1, then the object is simply assigned to the class of that single nearest neighbor. In k-NN regression, the output is the property value for the object. This value is the average of the values of k nearest neighbors. k-NN is a type of instance-based learning, or lazy learning, where the function is only approximated locally and all computation is deferred until function evaluation. Since this algorithm relies on distance for classification, normalizing the training data can improve its accuracy dramatically.
Both for classification and regression, a useful technique can be to assign weights to the contributions of the neighbors, so that the nearer neighbors contribute more to the average than the more distant ones. For example, a common weighting scheme consists in giving each neighbor a weight of 1/d, where d is the distance to the neighbor.